The Next Outage é um diário de falhas. Não porque admiramos o colapso, mas porque sabemos que ele é inevitável. Todo sistema do qual você depende — seja uma plataforma de nuvem bilionária ou um job em background que você escreveu anos atrás — vai falhar algum dia. Este blog é sobre esses momentos: o que os desencadeou, como se desenrolaram e, acima de tudo, o que podemos aprender antes que o próximo chegue.
Gostamos de imaginar falhas como explosões. Sistemas em chamas, dashboards acendendo como árvores de Natal, alarmes gritando. Mas a verdade é mais sutil — e mais perturbadora. As falhas raramente começam com um estrondo. Elas começam com um sussurro.
A noite começou silenciosa. Às 19h02, em um escritório envidraçado no centro da cidade, o último engenheiro do turno de uma empresa pegou seu casaco e saiu pela porta. O dashboard brilhava em verde, os gráficos estavam estáveis e o pager em silêncio. Parecia uma noite segura.
19h43 — A Primeira Consulta Perdida
Alguns clientes atualizaram seus carrinhos de compras, apenas para ver uma mensagem de erro. Seus navegadores não conseguiam resolver o domínio principal da empresa. Consultas de DNS falhavam de forma intermitente. As falhas eram dispersas, irregulares, quase aleatórias. O monitoramento sinalizou um pequeno pico de erros, mas o sistema automaticamente fazia novas tentativas, mascarando o problema. Ninguém percebeu.
20h15 — A Traição do Cache
Resolvedores de DNS ao redor do mundo começaram a servir registros desatualizados. Alguns usuários ainda conseguiam se conectar, mas outros estavam presos do lado de fora. Chamados de suporte começaram a pingar — poucos no início, fáceis de ignorar. Um engenheiro de plantão fez login, viu os serviços funcionando e atribuiu o problema a “questões de Provedor de Internet”.
Mas dentro do sistema, a bomba-relógio já estava armada. O DNS primária da empresa havia deixado de ser renovada 24 horas antes. Um descuido de $12.
20h42 — A Falha se Expande
O serviço de autenticação foi o primeiro a cair. Sem DNS funcional, a API de login não conseguia alcançar seu repositório de tokens. Usuários ficaram repentinamente bloqueados em suas contas. Aplicativos móveis travaram nas telas de carregamento. O monitoramento disparou, mas os alertas eram ruidosos e contraditórios: algumas regiões ainda funcionavam, outras não.
A confusão se instalou. Engenheiros se perguntavam: “Você está vendo isso?” “Funciona para mim na Virgínia, mas está quebrado na Europa.” “Pode ser problema de provedor de trânsito?”
21h07 — A Tempestade Estoura
Nesse momento, o Twitter já pegava fogo. Clientes não conseguiam fazer login, não conseguiam finalizar compras, não conseguiam sequer acessar a homepage. A falha era global, mas irregular, o que tornava o diagnóstico ainda mais difícil. Telas na war room piscavam em vermelho. Finalmente alguém investigou os registros DNS mais a fundo: os servidores de nomes autoritativos não estavam respondendo.
O silêncio caiu na sala do Slack. Os engenheiros perceberam o impensável — ninguém havia renovado o domínio. O registrador o havia colocado em período de carência.
21h31 — A Correria
Telefonemas foram feitos. Cartões de crédito digitados às pressas. Tentativas de renovação aconteceram. Mas o DNS não se cura instantaneamente. TTLs, caches, resolvedores recursivos — milhões de dispositivos no mundo já tinham memorizado as respostas erradas. Mesmo após a renovação do domínio, o veneno persistia. Engenheiros esvaziavam caches manualmente, reimplantavam containers, reiniciavam proxies — qualquer coisa para forçar uma atualização.
Enquanto isso, executivos estavam em videochamadas exigindo respostas. O CEO perguntou: “Quanto tempo até os clientes voltarem a ficar online?” Ninguém ousou se comprometer com um número. O DNS não tem um relógio que você possa acelerar.
23h52 — Sistemas se Arrastam de Volta
Lentamente, dolorosamente, os serviços retornaram. À meia-noite, o site já estava acessível para a maioria dos usuários. Às 2h da manhã, a recuperação estava quase completa. Engenheiros desabaram em suas cadeiras, exaustos. A correção era embaraçosamente simples: uma renovação de $12 esquecida. Mas o custo — em manchetes, reputação e transações perdidas — foi de milhões.
O que Poderiam Ter Feito Diferente
Essa falha não foi sobre complexidade. Não foi sobre casos extremos. Foi sobre propriedade básica e visibilidade. Todo o incidente poderia ter sido evitado se a equipe tivesse:
- Colocado o domínio em renovação automática com um método de pagamento corporativo (não o cartão pessoal de um engenheiro).
- Estabelecido monitoramento que alertasse quando um domínio ou certificado estivesse a menos de 30 dias da expiração.
- Definido claramente a responsabilidade por “dependências externas” como DNS, certificados e registradores — serviços que não vivem no stack principal, mas são igualmente críticos.
Em resumo: a falha não foi técnica. Foi organizacional.
Padrões de Falha a Reconhecer
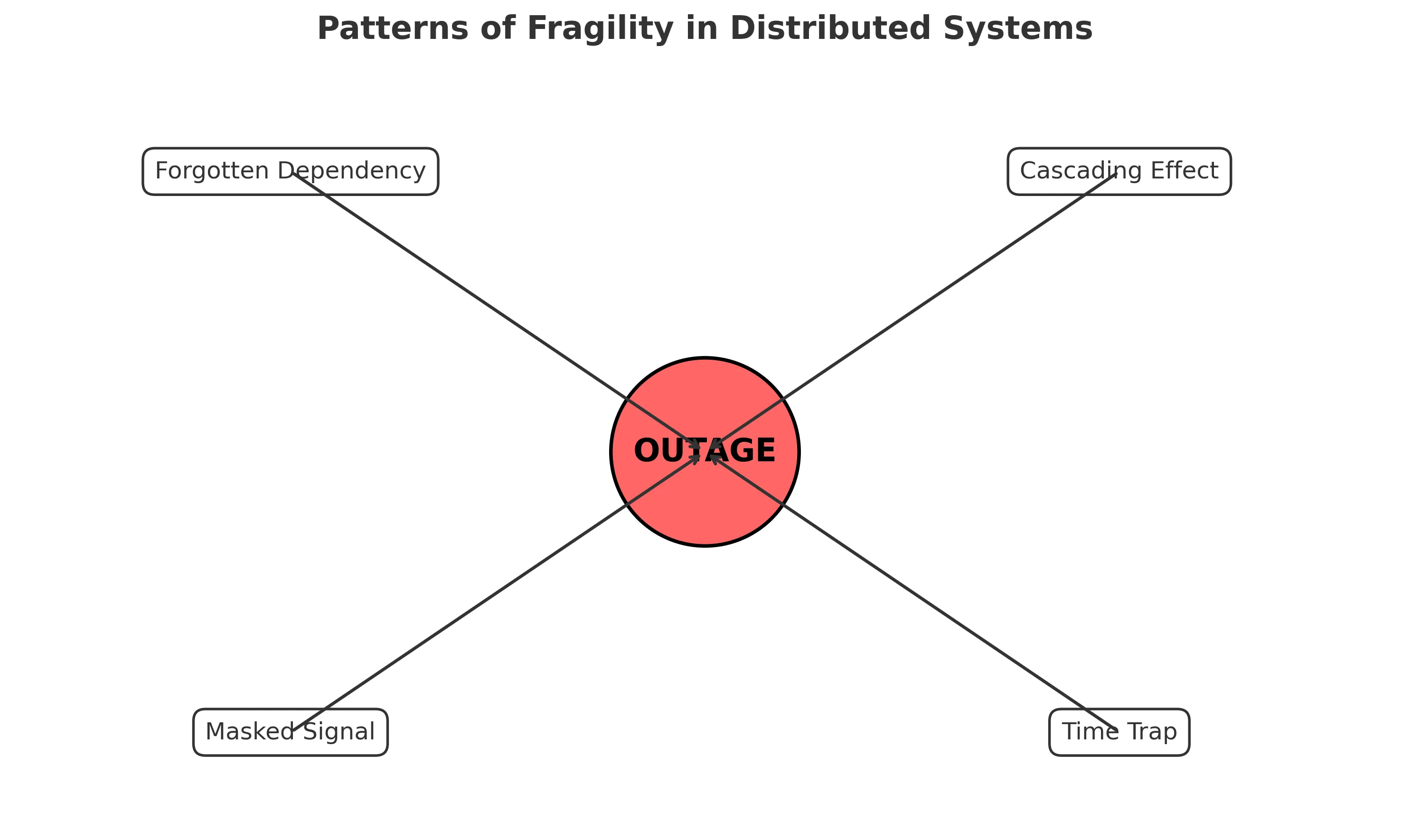
Esta história segue diversos padrões de falha bem conhecidos:
- A Dependência Esquecida: Componentes críticos (zonas DNS, certificados TLS, contas de nuvem) são assumidos como “problema de outra pessoa” até expirarem.
- O Efeito Cascata: Um único registro DNS ausente bloqueou a autenticação, que bloqueou logins, que paralisou pagamentos — multiplicando o impacto muito além da causa raiz.
- O Sinal Mascarado: As primeiras falhas de consulta foram escondidas por novas tentativas e caching, atrasando a percepção até que o problema fosse catastrófico.
- A Armadilha do Tempo: Mesmo após a renovação do domínio, caches globais de DNS fizeram a recuperação seguir no ritmo do resolvedor mais lento. Correções nem sempre se aplicam instantaneamente.
A Lição
Sistemas distribuídos não falham por causa das partes que monitoramos. Eles falham por causa dos cantos que ignoramos. Os componentes sem glamour e invisíveis — zonas DNS, certificados, cron jobs, tokens de API — vão te trair se não forem acompanhados com o mesmo rigor que seus serviços principais.
A menos que você trate desses pontos fracos no seu próprio ambiente, a próxima história não será apenas uma que você lê aqui. Será uma que você vai viver.